It resembles software used to compute differences between files (e.g. diff) or tools for sequence alignment which are commonly used in Bioinformatics. While CollateX shares some of the techniques and algorithms with those tools, it mainly aims for a flexible and configurable approach to the problem of finding similarities and differences in texts, sometimes trading computational soundness or complexity for the user's ability to influence results.
As such it is primarily designed for use cases in disciplines like Philology or – more specifically – the field of Textual Criticism where the assessment of findings is based on interpretation and therefore can be supported by computational means but is not necessarily computable.
Latest Version
Please refer to the documentation for detailed information about CollateX like its underlying concepts or usage instructions.
For alternative packages and license terms, please read the download section.
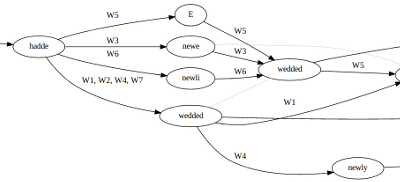
Snippet of a Variant Graph produced by CollateX
