To express textual variance, CollateX uses a graph-based data model (Schmidt 2009). On top of this model it supports several algorithms to progressively align multiple text versions.
The Gothenburg Model
Developers of CollateX and Juxta met for the first time in 2009 at a joint workshop of COST Action 32 and Interedition in Gothenburg. They started discussing, how the different concerns of computer-supported collation of texts could be separated such that these two as well as similar projects would have a common understanding of its process and could thus collaborate more efficiently on the development of collation tools as well as their components. As a first result of this ongoing discussion, the participants identified five distinct tasks present in any computer-supported collation workflow.
CollateX is designed around this separation of concerns.
Tokenization
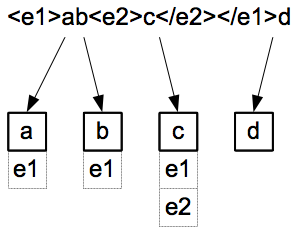
A tokenized text
While computers can compare a text's versions on a character-by-character basis, in the more common use case each version is first split up into parts – henceforth called tokens – so the comparison can be conducted on a more coarse-grained level where the tokens to be compared ideally correspond to the text's units which carry meaning. This pre-processing step is called tokenization and performed by a tokenizer; it can happen on any level of granularity, i.e. on the level of syllables, words, lines, phrases, verses, paragraphs or text nodes in a DOM.
Another service provided by tokenizers and of special value to the comparison of natural language texts relates to marked-up text versions: As most collation software primarily compares text versions based on their textual content, embedded markup would usually get in the way of this process and therefore needs to be discarded or “pushed in the background”, so the collation tool does not have to be concerned about the specifics of a text's encoding. At the same time it might be valuable to keep the markup context of every token for reference, for instance if one wanted to make use of it when comparing tokens.
The figure to the right depicts this process: The line on top shows a marked-up text, its content as the characters "a", "b", "c" and "d" – each representing a token – and "e1", "e2" as examples of embedded markup elements. A markup-aware tokenizer would not only split this version into 4 distinct tokens but transform it into a sequence of such tokens, with each token referring to its markup context.
For now CollateX offers a simple tokenizer, mainly serving prototyping purposes by either
- splitting plain text without any embedded markup on boundaries determined by whitespace, or
- evaluating a configurable XPath 1.0 expression on an XML-encoded text version which yields a list of node values as textual tokens.
While not offering a comprehensive tokenizer itself, CollateX can be combined with any such tool that suits your specific requirements. CollateX only expects you then to provide text versions in pre-tokenized form and define a token comparator function which – when called with any two tokens – evaluates to a match in case those two tokens shall be treated as equal, or a mismatch in case this should not be assumed. Formally speaking, a token comparator function defines an equivalence relation over all tokens for a collation. In processing tokens on the level of their equivalence defined by such a relation, CollateX is agnostic with regard to what constitutes a token in your specific use case, whether it is plain text, text with a markup context or not textual at all.
Detailed information about when and how to define your own notion of a token and its corresponding equivalence relation will be given in the following sections on CollateX' usage. Its built-in tokenizer will provide for an easy start. Later on you can opt for a more versatile tokenizer and/or token comparator function in order to enhance the accuracy of collation results.
Normalization/Regularization
With a configurable equivalence relation between tokens (defined via the aforementioned comparator function), CollateX can compare text versions which are comprised of arbitrary tokens sequences. For a larger number of use cases though, this flexibility of defining a fully customized comparator function is not really needed. It might suffice to normalize the tokens' textual content such that an exact matching of the normalized content yields the desired equivalence relation. For instance, in many cases all tokens of the text versions are normalized to their lower-case equivalent before being compared, thereby making their comparison case insensitive. Other examples would be the removal of punctuation, the rule-based normalization of orthographic differences or the stemming of words.
Just as with the tokenizer included in CollateX, its normalization options are rather simple. Beyond the mentioned case normalization and the removal of punctuation and/or whitespace characters, CollateX does not include any sophisticated normalization routines. Instead its API and supported input formats provide the user with options to plug in their own components when needed.
Alignment
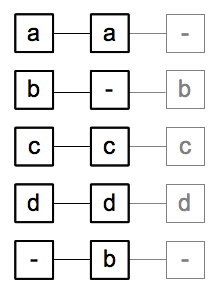
An alignment of 3 versions
After each version has been split into a sequence of tokens and each has been (optionally) normalized, the token sequences will be aligned. The alignment process constitutes the core of CollateX' functionality and is generally conducted by
- finding a set of matching tokens determined by the token equivalence relation, and
- aligning them via the insertion of gaps such that the token sequences of all versions line up optimally.
Looking at an example, assume that we have three versions: the first is comprised of the token sequence ["a", "b", "c", "d"], the second reads ["a", "c", "d", "b"] and the third ["b", "c", "d"]. A collation tool may align these three versions as depicted on the right. Each version occupies a column, matching tokens are aligned horizontally in a row, gaps are inserted as needed during the alignment process and denoted via a hyphen. Depending from which perspective one interprets this alignment table, one can say that the "b" in the second row was omitted in the second version or that it has been added in the first and the third. A similar statement can be made about the "b" in the last row, inverting the relationship of being added or omitted. Basic edit operations (e.g. those underlying the concept of edit distance) are thus implicitly expressed in such an alignment and can be interpreted accordingly to make assumptions about how a text has been changed.
The concept of sequence alignment and its tabular representation is well established in the field of Humanities Computing; alignment tables like the one shown can be encoded with well-known apparatus encoding schemes. In the parallel segmentation mode of TEI-P5's apparatus encoding scheme, to pick just one possible representation, each row would be encoded as a segment, with empty readings standing in for the gaps. Optionally, consecutive segments with matching readings for each version could be concatenated, so that for our example a possible encoding capturing the alignment information reads:
<app> <rdg wit="#w1 #w2">a</rdg> <rdg wit="#w3" /> </app> <app> <rdg wit="#w1 #w3">b</rdg> <rdg wit="w2" /> </app> <app> <rdg wit="#w1 #w2 #w3">cd</rdg> </app> <app> <rdg wit="#w2">b</rdg> <rdg wit="#w1 #w3" /> </app>
Also beyond the field of Humanities Computing, the technique of sequence alignment has many application areas; Bioinformatics for example has addressed it as a computational problem thoroughly in recent years. In this context and as part of the larger field of pattern matching, extensive research exists on the topic. CollateX primarily strives to make the results of this research available to textual scholars. For this import of computational methods it has to be noted though that – generally speaking – the assessment of findings in the Humanities is based on interpretation. While it certainly can be supported by computational means, it is not necessarily computable. As a concrete consequence of that difference in methodology, CollateX offers its users not one algorithm optimized by specific criteria, but a choice between several alignment algorithms so they can select the one that supports their expected results best, always assuming that any computational heuristic may fail in the light of subjective judgement.
Analysis/Feedback
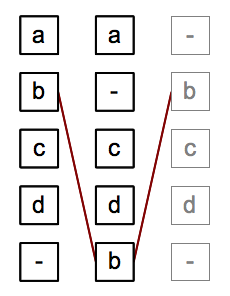
Analyzing an alignment
As the heuristic approach to the problem of sequence alignment may not yield the desired result, a further analysis of the alignment may be necessary. Echoing the example from the above section, evidence not accessible to the collation tool (e.g. because it was not encoded in the text versions at hand) might support the assumption of token "b" in row 2 and 5 as not only being added/omitted but transposed/moved (see figure to the right). While heuristic algorithms may compute transpositions as part of the alignment process, the correctness of such a computation, given external evidence and its heuristic nature, obviously cannot be ensured.
An additional (possibly manual) analysis of the alignment result therefore may alleviate that deficiency by introducing the possibility of a feedback cycle, in which users edit the alignment and feed their knowledge back into the alignment process for another run delivering enhanced results. The declaration of pre-determined alignments between specific tokens and the parametrization of optimizing algorithms along the requirements of a specific use case would be such feedback information which influences results substantially.
CollateX offers rudimentary support for tailoring alignment results to a user's specific requirements, mainly through its Java API. It is an area in need for improvement, particularly with regard to its ease of use.
Visualization
The final concern of any collation workflow relates to the visualization of its results. As the broad variety of building principles, layouts and notational conventions found in printed apparatuses already suggests, representing textual variance is a complex problem on its own. Software like Juxta has demonstrated the potential of digital media to cope with this complexity in innovative ways. For CollateX, the visualization of results is deemed out of scope at the moment. Instead it provides several output formats which facilitate the integration with software in charge of visualizing results, be it in printed or in digital form.
The Data Model: Variant Graphs
The tabular representation of collation results as shown in the section on sequence aligment is popular, in the Humanties and beyond. CollateX can output results in this representation but uses a different one internally for modelling textual variance: variant graphs.
Variant graphs are the central data structure of CollateX. Any generated output from CollateX is a derivation, providing different views on it. The idea of a graph-oriented model for expressing textual variance has been originally developed by Desmond Schmidt (Schmidt 2008, Schmidt 2009, Schmidt 2009a) and proved to be particularly well suited as a data model for computer-supported collation. The following figure taken from one of his publications illustrates it:

Schmidt/Colomb's Variant Graph Model
Variant graphs are in principal directed and acyclic. They are comprised at least of a start and end node/vertex ("s" and "e" in the figure above) and can be traversed from the one to the other via labelled edges. The labels on each edge contain content segments of compared text versions and a set of identifiers/sigils, denoting the versions which contain the respective content of an edge's label. Thus
- common segments of multiple text versions can be merged in a variant graph,
- differing segments result in the graph branching at nodes, while
- each version can still be retrieved from the graph by traversing it along the edges labeled with the appropriate identifier of that version.
Following these principles, the depicted variant graph models three text versions A, B and C with the following content (markup omitted):
| A | Queste è l'ultima traccia d'un antico acquedotto di sguardi, una orbita assorta e magica: |
|---|---|
| B | Queste è l'ultima cenno d'un antico acquedotto di sguardi, la sua curva sacra e muta: |
| C | Queste è l'ultima porta d'un antico acquedotto di sguardi, la sua curva sacra e solitaria: |
In order to account for the separation of concerns laid out above, CollateX' implementation of Schmidt's model adjusted the latter slightly. Instead of labelling the edges of a variant graph with two attributes – the content as well as the sigils of text versions containing it – the edges of variant graphs in CollateX are only labeled with sigil sets. The version's content segments – in the form of partial token sequences – have been moved to the nodes/vertices. The ending of the example graph then looks like this (with sigils being mapped from A, B, C to W1, W2, W3):
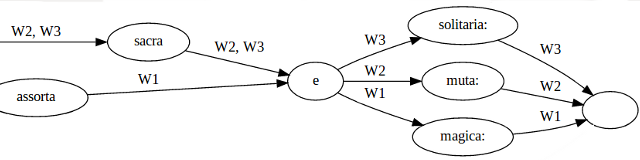
CollateX' Variant Graph Model
The above illustration does not reveal the internal structure of the graph completely insofar as the nodes' labels in this figure are a simplification. For instance, the second node in the graph (read from left to right) is labeled "sacra", with the two versions W2 and W3 "sharing some content". More precisely though and in line with the above definition of tokens and their equivalence relation, W2 and W3 do not "share some content". Instead they both contain a token with the content "sacra", both deemed to be equal according to the definition of a specific token comparator function. In the graphical representation of the variant graph above, this subtle distinction is not made and both tokens are just represented via their common textual content. In CollateX' data model though, this distinction is still relevant and represented: Each node/vertex in a variant graph is not modelled via textual content (as it would be the case when translated directly from Schmidt's model) but as a set of tokens per node originating from one or more versions, with all tokens in such a set belonging to the same equivalence class.
The described change to Schmidt's model serves mainly two purposes: Firstly, it allows for arbitrary tokens to be compared and their commonalities, differences as well as their sequential order to be represented in a graph structure. Secondly, CollateX' graph model is easy to transform into the tabular representation introduced further above by ranking the graph's nodes in topological order and aligning tokens which belong to nodes of the same rank.
It has to be noted that also in this data model, the transposition of tokens still remains a problematic case. Like in Schmidt's model, CollateX represents the transposition of a token (or more precisely: it's content) as a link between nodes (in the case of Schmidt' model: edges) containing the transposed segment. The link is undirected and does not form part of a variant graph's traversal scheme because transposition links would break the assertion of a variant graph's acyclic nature and consequently the ability to sort it topologically. While the linking of nodes can represent transposed segments sufficiently, it is superimposed on a variant graph, i.e. it does not integrate well with it. Future work in this area may yield a more concise representation.
Alignment Algorithms
CollateX strives for maximum flexibility on the users' side when comparing text versions and adjusting the results to their requirements. One part of this flexibility is rooted in the support of several alignment algorithms users can switch between and experiment with.
Currently three algorithms have been implemented. They all operate on variant graph structures and belong to the group of progressive alignment algorithms. Instead of comparing all versions at once, they
- start by comparing two versions,
- transform the result into a variant graph, then
- progressively compare another version against that graph, and
- merge the result of that comparison into the graph,
- repeating the procedure until all versions have been merged.
On the one hand, the progressive approach is advantageous because it reduces the problem of comparing an arbitrary number of versions to the simpler comparison of a single version with a variant graph representing several ones. The disadvantage on the other hand is the occasional dependence of the result on the order in which versions are merged into the graph (Spencer 2004). Adding tools to deal with this dependency, e.g. by performing a phylogenetic analysis to determine an optimal order, is planned for a future version.
Dekker
The most mature algorithm offered by CollateX thus far has been developed by Ronald Haentjens Dekker (Dekker 2011). It aligns an arbitary number of text versions, optimizes the local alignment of partial tokens sequences (phrases) and detects transpositions.
Needleman-Wunsch
The Needleman-Wunsch algorithm (Needleman 1970) is a well-known global alignment algorithm broadly applied in Bioinformatics and the social sciences. Based on dynamic programming, this algorithm searches for an optimal alignment of an arbitrary number of versions by consulting a scoring function which penalizes the insertion of gaps. It does not take the possibility of transposed segments into account though.
The scoring function in CollateX' implementation can not be freely configured at the moment; the gap penality is assumed to be constant and equals the score of a match.
MEDITE
Only recently added to the code base, this algorithm takes its name from a pairwise alignment algorithm developed by Julien Bourdaillet and Jean-Gabriel Ganascia (Bourdaillet 2007). It is based on suffix trees for the search of maximal unique matches between text versions and the A* algorithm for optimizing the alignment. Like Dekker's algorithm, it takes transpositions into account while doing so.
CollateX' implementation of this algorithm is in an experimental stage. While it already delivers promising results, it has not been fully optimized and – above all – not been extensively tested. In the case of issues with this algorithm, the CollateX team would appreciate feedback. Alternatively users can download the original version of MEDITE written by the algorithm's authors.
Input
This section describes the different input formats CollateX supports. Besides the contents of a text's versions to be compared, the input may also include parameters, i. e. the alignment algorithm to be used.
Plain Text
Like any collation tool, CollateX can process text versions provided as plain text. As CollateX is written for the Java Virtual Machine, internally the comparison of plain text is based on the JVM's string type and thus on 16-bit Unicode characters.
Depending on the way CollateX is used, plain text version can also be provided in other encodings supported by the Java Platform and will be converted to Unicode before comparison. The command line interface is one such interface which supports character set conversions.
Plain text version are always subject to tokenization and optional normalization of the resulting token sequence before they will be compared with each other.
JSON
As a more flexible format, CollateX supports input in JavaScript Object Notation (JSON). A set of text versions to be compared can be JSON encoded as follows:
{
"witnesses" : [
{
"id" : "A",
"content" : "A black cat in a black basket"
},
{
"id" : "B",
"content" : "A black cat in a black basket"
},
{
"id" : "C",
"content" : "A striped cat in a black basket"
},
{
"id" : "D",
"content" : "A striped cat in a white basket"
}
]
}
JSON input always consists of a single root object wrapping input data. The root object has one required property containing the versions to be compared which (for historical reasons) is named witnesses. The value of this property is an array (a list) of objects in turn, with each object representing a version. The order of the array elements determines the order in which they are processed by an alignment algorithms, i.e. in which versions are merged into a variant graph.
Each object in the witnesses array must have a unique identifier in the required property id. This identifier will be used in the output to reference a particular version. Besides the identifier each object must describe the content of the version. The content can either be specified as a string property named content as shown above. In this case the version is treated like a plain text version with tokenization and normalization taking place before the alignment.
Another option is to provide the content of versions in tokenized (and optionally normalized) form:
{
"witnesses" : [
{
"id" : "A",
"tokens" : [
{ "t" : "A", "ref" : 123 },
{ "t" : "black" , "adj" : true },
{ "t" : "cat", "id" : "xyz" }
]
},
{
"id" : "B",
"tokens" : [
{ "t" : "A" },
{ "t" : "white" , "adj" : true },
{ "t" : "kitten.", "n" : "cat" }
]
}
]
}
Instead of providing a property content for a version, one can provide a sequence of tokens via the property tokens. The version's property value must be a list with one object per token Each token object in turn must at least contain a property t, which defines its content. Accordingly, in the example above, version "A" has the tokens ["A", "black", "cat"] whereas version "B" is comprised of the token sequence ["A", "white", "kitten"].
Optionally a normalized reading of the token can be provided in the property n. Again, in the example above, that means the last token of version "B" is normalized from the reading "kitten" to the reading "cat", thus facilitating a match of "kitten" with the last token of version "A".
Apart from these 2 defined properties t and n, token objects can contain an arbitrary number of additional properties. Additional properties will not be interpreted by CollateX but just be passed through, reappearing in the output unchanged. Properties like ref, adj or id in the example would be such additional properties of a token object. Users of the JSON input can make use of this pass-through mode e.g. in order to uniquely identify aligned tokens independently of their (possibly non-unique) content.
When using interfaces like the HTTP service of CollateX, JSON encoded input can contain optional parameters controlling the collation process. You can set the alignment algorithm for instance by providing a property algorithm in the root object with one of the values "needleman-wunsch", "medite" or "dekker" (the default):
{
"witnesses": [ … ],
"algorithm": "needleman-wunsch"
}
There is also limited support for customizing the token comparator function. Via JSON, two functions are available:
{
"witnesses": [ … ],
"algorithm": "…",
"tokenComparator": { type: "equality" }
}
The default function, which can also be explicitly configured like shown above, tests for exact equality of the normalized token content. An alternative is the use of approximate matching via a Levenshtein/edit distance threshold for matching tokens:
{
"witnesses": [ … ],
"tokenComparator": {
"type": "levenshtein",
"distance": 2
}
}
For approximate matching, the type property of the token object descring the token comparator function must be assigned the value "levenshtein". The optional property distance defines the maximum edit distance between two normalized tokens strings which is still considered to be a match. An edit distance of 1 is the default.
XML
XML-encoded text versions are also supported by CollateX, though the ability to preserve the markup context during the collation process is fairly limited at the moment when not using the Java API.
Out of the box, you can compare XML documents via the command line interface. On the command line, CollateX accepts XML documents with arbitrary tag sets. All it needs is an XPath 1.0 expression that evaluates to a node set for each document. The text content of each node in such a set equals a token. For example, the XPath expression "//w" would result in a text version for each XML document with the sequence of text segments enclosed in <w/> elements as tokens.
Output
CollateX supports several formats to represent collation results.
JSON
In conjunction with JSON being supported as an input format, collation results can be output in JSON as well. The schema of such output resembles matrices commonly encountered in sequence alignment representations, and looks as follows for the second example given in the section on JSON input (indentation/whitespace added for easier readability):
{
"witnesses":["A","B"],
"table":[
[ [ {"t":"A","ref":123 } ], [ {"t":"A" } ] ],
[ [ {"t":"black","adj":true } ], [ {"t":"white","adj":true } ] ],
[ [ {"t":"cat","id":"xyz" } ], [ {"t":"kitten.","n":"cat" } ] ]
]
}
The root object always contains 2 properties. The value of property witnesses is a list of a all compared text versions, represented by their sigils/identifiers. The witness list's order is significant insofar as the contents of the second property table – which contains the actual alignment – is ordered accordingly.
The tabular alignment data is represented as a list of lists, with
- the parent list containing one entry per aligned segment, and
- each segment/ child list containing sets of tokens from each compared version.
Because aligned segments can span multiple tokens, the aligned token sets of each text version are also represented as lists, we effectively have 3 levels:
- On the top-level, each list entry represents a set of aligned segments from different text versions.
- On the intermediate level, each list entry represents a set of tokens from a particular text version.
- On the lowest level, each list entry is an object representing a single token.
Out example output thus is comprised of 3 segments, each containing exactly one token per text version. The order in which the token sets are listed equals the order of the text versions as listed in the property witnesses. Thus "A" from text version A is aligned with "A" from text version B, "black" from text version A is aligned with "white" from text version B, and so on.
Additions and omissions are expressed via empty token sets, e.g. an alignment of
{
"witnesses":["X","Y"],
"table":[
[ [ {"t":"A" } ], [ {"t":"A" } ] ],
[ [ {"t":"brown" } ], [] ],
[ [ {"t":"dog" } ], [ {"t":"dog" } ] ]
]
}
could be interpreted as "brown" being added in version "X" or omitted in version "Y".
Please note that transpositions are not represented explicitly in tabular output formats like this one. While the detection of transpositions affects the alignment, the links between tokens which are assumed to be transposed by the collation algorithm are not given in this output format. Support for transpositions in tabular representations of collation results will be added in a future version of CollateX.
TEI P5
The tabular representation of alignments described in the previous section can be encoded in a number of ways.
<?xml version='1.0' encoding='UTF-8'?>
<cx:apparatus
xmlns:cx="http://interedition.eu/collatex/ns/1.0"
xmlns="http://www.tei-c.org/ns/1.0">
A
<app>
<rdg wit="A">black</rdg>
<rdg wit="B">white</rdg>
</app>
<app>
<rdg wit="A">cat</rdg>
<rdg wit="B">kitten.</rdg>
</app>
</cx:apparatus>
XML
<alignment xmlns="http://interedition.eu/collatex/ns/1.0">
<row>
<cell sigil="w1">Auch hier </cell>
<cell sigil="w2">Ich </cell>
<cell sigil="w3">Ich </cell>
</row>
<row>
<cell sigil="w1">hab </cell>
<cell sigil="w2">hab </cell>
<cell sigil="w3">hab </cell>
</row>
<row>
<cell sigil="w1">ich </cell>
<cell sigil="w2">auch hier </cell>
<cell sigil="w3">auch hier </cell>
</row>
<row>
<cell sigil="w1">wieder ein Plätzchen</cell>
<cell sigil="w2">wieder ein Pläzchen</cell>
<cell sigil="w3">wieder ein Pläzchen</cell>
</row>
</alignment>
GraphML
The GraphML-formatted output of a variant graph is suitable for import of (possibly larger) graphs in tools for complex graph analysis and visualization, e. g. Gephi. For an example GraphML document, take a look at sample output from the web console.
GraphViz DOT
digraph G {
v301 [label = ""];
v303 [label = "A"];
v304 [label = "black"];
v306 [label = "white"];
v305 [label = "cat"];
v302 [label = ""];
v301 -> v303 [label = "A, B"];
v303 -> v304 [label = "A"];
v303 -> v306 [label = "B"];
v304 -> v305 [label = "A"];
v306 -> v305 [label = "B"];
v305 -> v302 [label = "A, B"];
}
The Command Line Interface
usage: collatex [<options>]
(<json_input> | <witness_1> <witness_2> [[<witness_3>] ...])
-a,--algorithm <arg> progressive alignment algorithm to
use 'dekker' (default), 'medite',
'needleman-wunsch'
-cp,--context-path <arg> URL base/context path of the
service, default: '/'
-dot,--dot-path <arg> path to Graphviz 'dot',
auto-detected by default
-f,--format <arg> result/output format: 'json', 'csv',
'dot', 'graphml', 'tei'
-h,--help print usage instructions
-ie,--input-encoding <arg> charset to use for decoding non-XML
witnesses; default: UTF-8
-mcs,--max-collation-size <arg> maximum number of characters
(counted over all witnesses) to
perform collations on, default:
unlimited
-mpc,--max-parallel-collations <arg> maximum number of collations to
perform in parallel, default: 2
-o,--output <arg> output file; '-' for standard output
(default)
-oe,--output-encoding <arg> charset to use for encoding the
output; default: UTF-8
-p,--port <arg> HTTP port to bind server to,
default: 7369
-s,--script <arg> ECMA/JavaScript resource with
functions to be plugged into the
alignment algorithm
-S,--http start RESTful HTTP server
-t,--tokenized consecutive matches of tokens will
*not* be joined to segments
-xml,--xml-mode witnesses are treated as XML
documents
-xp,--xpath <arg> XPath 1.0 expression evaluating to
tokens of XML witnesses; default:
'//text()'ECMA/JavaScript Callbacks
The RESTful Web Service
java -jar collatex-tools-1.7.1.jar --http
The CollateX service is callable via HTTP POST requests to /collate.
It expects input formatted in JavaScript Object Notation (JSON) as the request body;
accordingly the content type of the HTTP request must be set to application/json by the client.
The output format of the collator, contained in the response to an HTTP POST request, can be chosen via
an Accept HTTP header in the request. The following output formats are supported:
| application/json | (per default) the tabular alignment of the witnesses' tokens, represented in JSON |
|---|---|
| application/tei+xml | the collation result as a list of critical apparatus entries, encoded in TEI P5 parallel segmentation mode |
| application/graphml+xml | the variant graph, represented in GraphML format |
| text/plain | the variant graph, represented in Graphviz' DOT Language |
| image/svg+xml | the variant graph, rendered as an SVG vector graphics document |
For further examples, take a look at sample output from the web console.
The HTTP-based JavaScript API
Enables the use of CollateX' RESTful API via JavaScript … Based on YUI framework …
Requirements
Add dependencies to header … YUI library plus CollateX module …
<script type="text/javascript" src="http://yui.yahooapis.com/3.8.1/build/yui/yui-min.js"></script> <script type="text/javascript" src="http://collatex.net/demo/collatex.js"></script>
Substitute URL prefix [ROOT] with the base URL of your installation, e.g.
this one for the installation you are currently looking at …
YUI module interedition-collate available now … supports cross-domain AJAX requests via
CORS …
Sample usage
YUI().use("node", "collatex", function(Y) {
new Y.CollateX({ serviceUrl: "http://collatex.net/demo/collate" }).toTable([{
id: "A",
content: "Hello World"
}, {
id: "B",
tokens: [
{ "t": "Hallo", "n": "hello" },
{ "t": "Welt", "n": "world" }
]
}], Y.one("#result"));
});
… toTable() takes witness array as first parameter; second parameter is DOM node which serves as container for
the resulting HTML alignment table …
… generic collate(witnesses, callback) as well as methods for other formats available:
toSVG(), toTEI(), toGraphViz() …
… configuration of a collator instance via methods like withDekker(), withFuzzyMatching(maxDistance) …
Resources/ Bibliography
- Bourdaillet 2007
- Bourdaillet J. and Ganascia J.-G., 2007. Practical block sequence alignment with moves. LATA 2007 - International Conference on Language and Automata Theory and Applications, 3/2007.
- Collate
- Robinson, P., 2000. Collate.
- Dekker 2011
- Dekker, R. H. and Middell, G., 2011. Computer-Supported Collation with CollateX: Managing Textual Variance in an Environment with Varying Requirements. Supporting Digital Humanities 2011. University of Copenhagen, Denmark. 17-18 November 2011.
- Juxta 2013
- Performant Software Solutions LLC, 2013. Juxta.
- Needleman 1970
- Needleman, Saul B. and Wunsch, Christian D., 1970. A general method applicable to the search for similarities in the amino acid sequence of two proteins. Journal of Molecular Biology 48 (3), 443–53.
- NMerge 2012
- Schmidt, D., 2012. NMerge. The nmerge Java library/commandline tool for making multi-version documents.
- Schmidt 2008
- Schmidt, D., 2008. What's a Multi-Version Document. Multi-Version Documents Blog.
- Schmidt 2009
- Schmidt, D. and Colomb, R., 2009. A data structure for representing multi-version texts online. International Journal of Human-Computer Studies, 67.6, 497-514.
- Schmidt 2009a
- Schmidt, D., 2009. Merging Multi-Version Texts: a Generic Solution to the Overlap Problem.” Presented at Balisage: The Markup Conference 2009, Montréal, Canada, August 11 - 14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). doi:10.4242/BalisageVol3.Schmidt01.
- Spencer 2004
- Spencer M., Howe and Christopher J., 2004. Collating Texts Using Progressive Multiple Alignment. Computers and the Humanities. 38/2004, 253–270.
- Stolz 2006
- Stolz, M. and Dimpel F. M., 2006. Computergestützte Kollationierung und ihre Integration in den editorischen Arbeitsfluss. 2006.
